One of the most effective techniques used in modern RAG systems is query expansion. It is a reliable method that engineers can apply to significantly improve retriever performance.
In this article, we walk through an experiment where we build a BM25 retrieval system, apply query expansion, and evaluate its impact using Precision, Recall, and MRR.
What is Query Expansion?
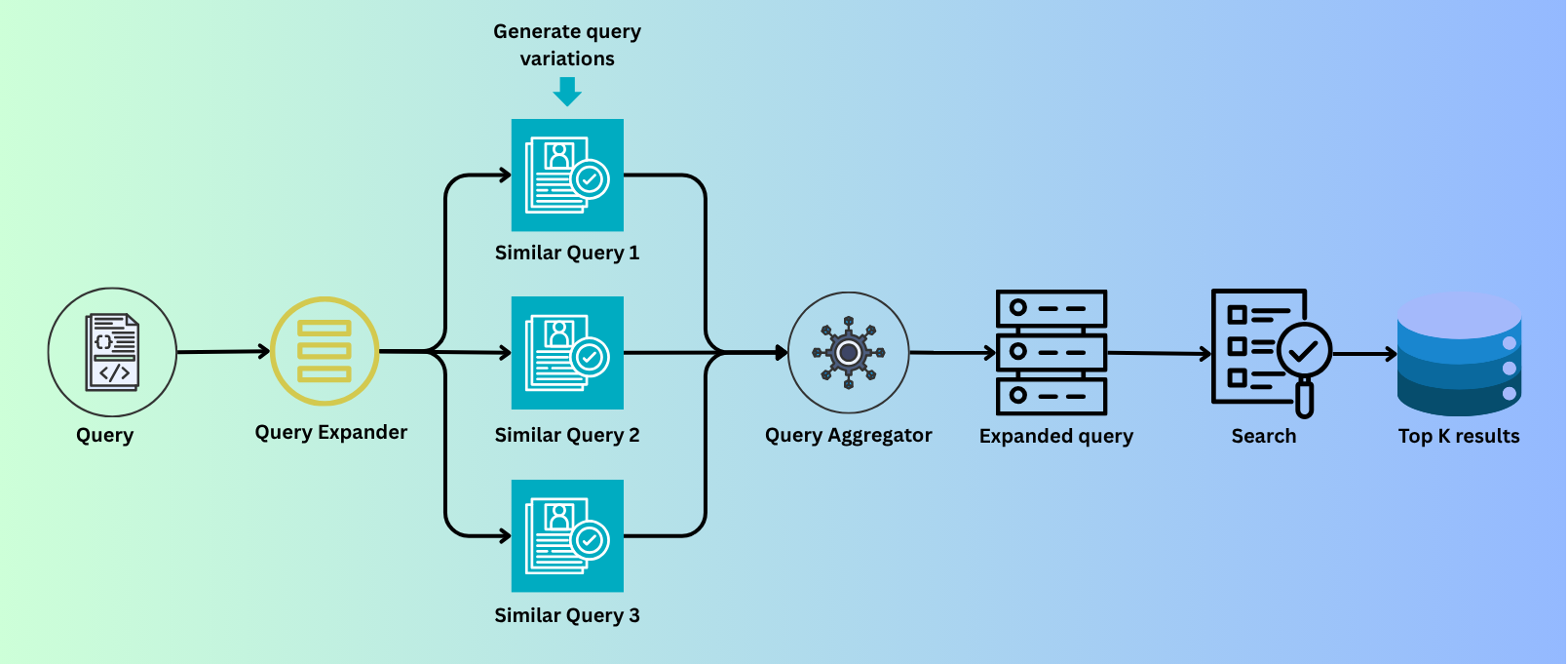
Query expansion is a simple yet powerful technique widely used in modern AI systems. The idea is to expand a single query into multiple variations that retain the same meaning but use different wording.
Instead of directly tokenizing the original query and performing a search, we introduce a query expansion layer on top of the retrieval process. In simple terms, we generate multiple semantically similar queries, increasing the chances of retrieving more relevant results.
Example
Original Query: "late payment fee"
Without query expansion, a retriever like BM25 will search for the exact terms “late”, “payment”, and “fee”. This means it may miss relevant documents containing related terms such as “charges”, “penalty”, or “overdue”.
To address this, we expand the original query into a richer version:
Expanded Query: "late payment fee penalty charges overdue"
Now, the query includes multiple semantically similar terms. This increases coverage and helps the retriever match a broader set of relevant documents. Given the lexical nature of BM25, this often leads to better retrieval performance.
While query expansion can also benefit dense retrievers, in this experiment we will focus on BM25. We will evaluate its performance using metrics such as Precision@5, Recall@5, and MRR@5 to determine whether query expansion leads to measurable improvements.
Before diving into the experiment results, let’s first look at some of the most widely used query expansion techniques. The Query Expander shown above is a generic component that can be implemented using different techniques, such as dictionary-based methods, LLM-based expansion, or PRF.
1. Dictionary-Based (Rule-Based) Expansion
In this approach, we use a predefined mapping of words to their synonyms.
Example:
Query: "late payment fee"
Expanded: "late payment fee penalty charges"
We maintain a domain-specific dictionary that maps key terms to their related words:
"fee": ["charge", "penalty"]
"lost": ["stolen", "missing"]
When a query is received, we look up each term in the dictionary, retrieve its synonyms, and expand the query accordingly. This improves the effectiveness of lexical search methods like BM25.
Pros
- Simple to implement
- Fast execution
- Fully controllable
Cons
- Limited vocabulary
- Does not generalize well
When to Use
- Small systems
- Domain-specific applications (e.g., credit card documentation)
2. LLM-Based Expansion (Modern Approach)
In this approach, we use a Large Language Model (LLM) to generate multiple variations of a query using prompt-based instructions.
The idea is to pass the original query to the LLM and ask it to generate 3–5 semantically similar queries with different wording.
Example:
Query: "minimum amount due"
Expanded queries:
minimum payment required
outstanding payment obligation
due balance amount
This method is powerful because it goes beyond simple synonym replacement. The model understands the intent of the query and generates variations based on meaning rather than just keywords.
Pros
- Significant improvement in recall
- Handles unseen or complex queries
- No need for manual rule creation
Cons
- Additional cost (API usage)
- Increased latency
- May introduce noisy or less relevant variations
When to Use
- Production-grade RAG systems
- Scenarios where recall is critical
3. Pseudo-Relevance Feedback (PRF) / Top-K Expansion
This is a data-driven technique that does not require any external knowledge source.
The process works as follows:
- Use the original query to retrieve top-K relevant documents (e.g., using BM25)
- Extract important or frequent terms from these documents
- Expand the original query using those terms
- Perform retrieval again with the expanded query
Example:
Query: "credit limit"
Top results may contain terms like:
maximum credit
available limit
card account
Expanded query:
credit limit maximum credit available limit card account
Pros
- No external API cost
- Adapts to your dataset
- Highly effective in traditional IR systems
Cons
- Depends on the quality of initial retrieval
- Can reinforce incorrect results (query drift)
When to Use
- Classic information retrieval systems
- Scenarios where you want data-driven query expansion
Implementation & Results
Objective: The goal of this experiment is to build a retrieval system that fetches relevant terms and conditions sections based on user queries and uses those retrieved chunks to generate answers.
In this article, we focus only on the retriever component, not the generation step.
Experimental Setup
- Retriever used: BM25 (chosen for simplicity and strong lexical performance)
- Evaluation dataset: 100 sample queries (ground truth)
Metrics used:
- Precision@5
- Recall@5
- MRR (Mean Reciprocal Rank)
The objective is to evaluate whether query expansion improves retrieval performance.
Baseline (Without Query Expansion)
| Precision@5 | 0.168 |
| Recall@5 | 0.4683 |
| MRR | 0.4885 |
Dictionary-Based Query Expansion
We expanded queries using a predefined dictionary to improve lexical coverage.
| Precision@5 | 0.1780 |
| Recall@5 | 0.4967 |
| MRR | 0.5042 |
Observation: There is a noticeable improvement in both Recall and MRR. While the gains are modest, they demonstrate that even simple rule-based query expansion can enhance retriever performance.
LLM-Based Query Expansion
For this approach, we used a Gemini model to generate multiple query variations. (You can also use open-source models available on Hugging Face.)
| Precision@5 | 0.2020 |
| Recall@5 | 0.5567 |
| MRR | 0.5685 |
Observation: This significantly improves performance across all metrics. Recall improved by ~19.6% compared to the baseline MRR also shows a strong increase, indicating better ranking of relevant results
Query expansion improves recall more than precision. This is expected because expanding the query increases coverage, allowing the retriever to match more documents. However, this can also introduce noise, which is why precision improvements are smaller compared to recall.
Conclusion
From the experimental results, it is clear that query expansion improves retrieval performance when implemented correctly. Both dictionary-based and LLM-based approaches show measurable gains over the baseline, with LLM-based expansion delivering the most significant improvements.
However, choosing the right approach depends on the trade-off between latency and accuracy:
If accuracy is the priority, LLM-based query expansion is the better choice due to its ability to capture semantic meaning.
If latency and cost are critical, simpler methods like dictionary-based or Top-K (PRF) expansion are more suitable.
In practice, designing an effective retrieval system requires carefully balancing these trade-offs based on the specific use case.
Until next time, happy learning!
Full code repo: View on GitHub
LinkedIn profile: Connect on LinkedIn
← Back to Articles