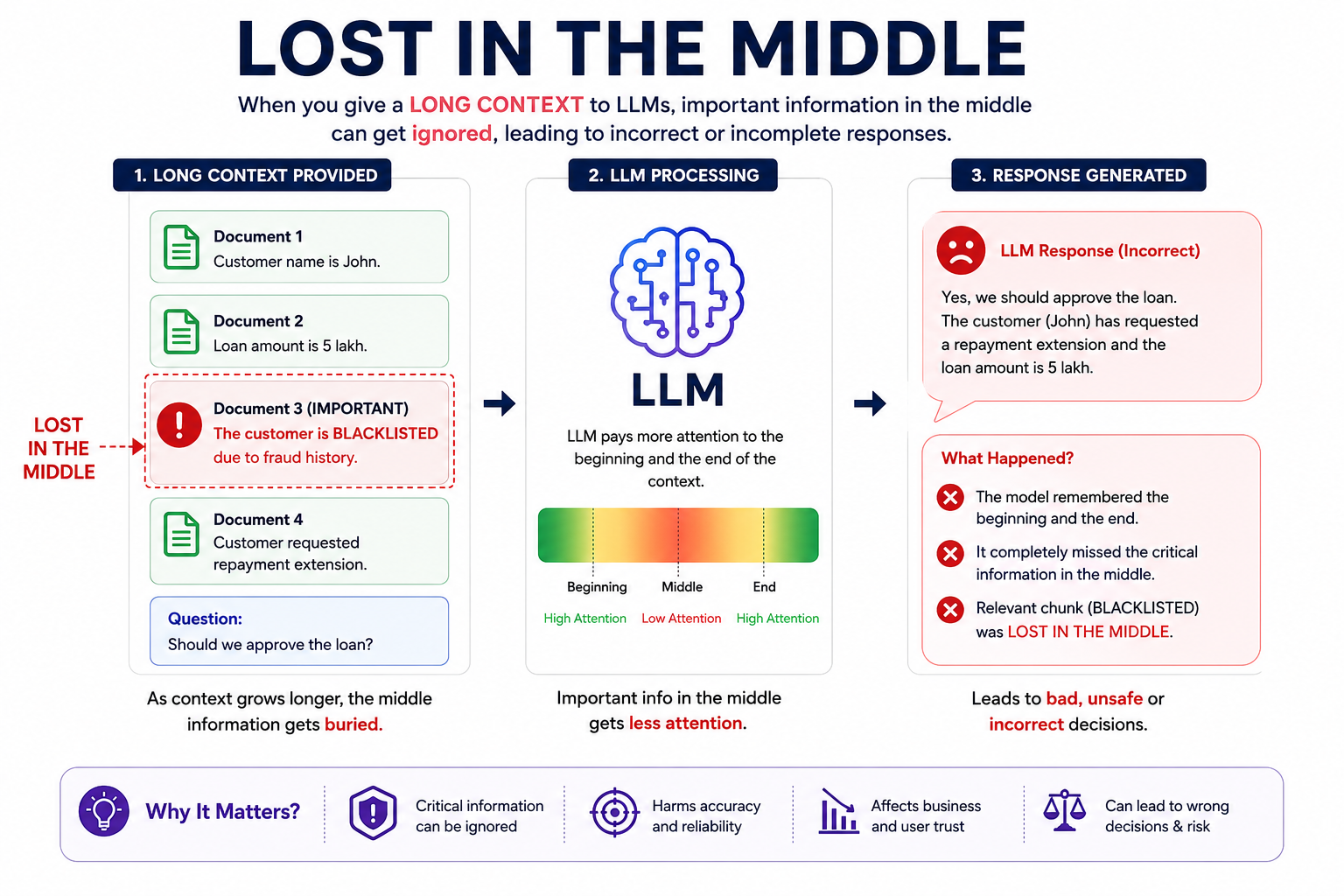
While building production-ready LLM-based solutions like Agentic AI or RAG, we may face very uncommon problems that can cause very big issues in production.
One such issue is called "Lost in the Middle", which can directly affect the output of the LLM by ignoring the most important information from the context we pass.
In this article, we will understand what this issue is, why it occurs, how to detect it while building systems and in production, and also how to solve this problem using different techniques.
Lost in the Middle
As the phrase says, Lost in the Middle is a failure pattern in LLMs where the model ignores or under-utilizes the information that appears in the middle of a long context.
Simple Example
Imagine this as a prompt:
You are a helpful assistant. Document 1: Customer name is John. Document 2: Loan amount is 5 lakh. Document 3: IMPORTANT: The customer is BLACKLISTED due to fraud history. Document 4: Customer requested repayment extension. Now answer: Should we approve the loan?
If the context becomes large enough, many models may:
- Remember “John”
- Remember “5 lakh”
- Remember the last repayment request
But completely miss:
because it was buried in the middle.
That is “Lost in the Middle.”
Here, we need to focus on the term "long context." Whenever we pass very long context to the LLM, it tends to miss or deprioritize the information in the middle of that long context.
This is even true for LLMs with large context sizes, like the Gemini family of models.
An important misconception is that if a model has a 1M token context window, then it gives equal priority to all that context, which is not true.
Why does this happen?
At a high level, this happens because:
1. Attention dilution
This is related to how transformers read the context. They do not read it sequentially like humans.
They use self-attention, where each word has to attend to every other word. It works really well for small contexts like 100 tokens.
Now, if the context grows to 200k tokens, then each word attending to every other word causes the weights to become smaller and smaller.
This is called attention dilution.
That means LLMs can understand smaller contexts better than larger ones.
2. Position bias
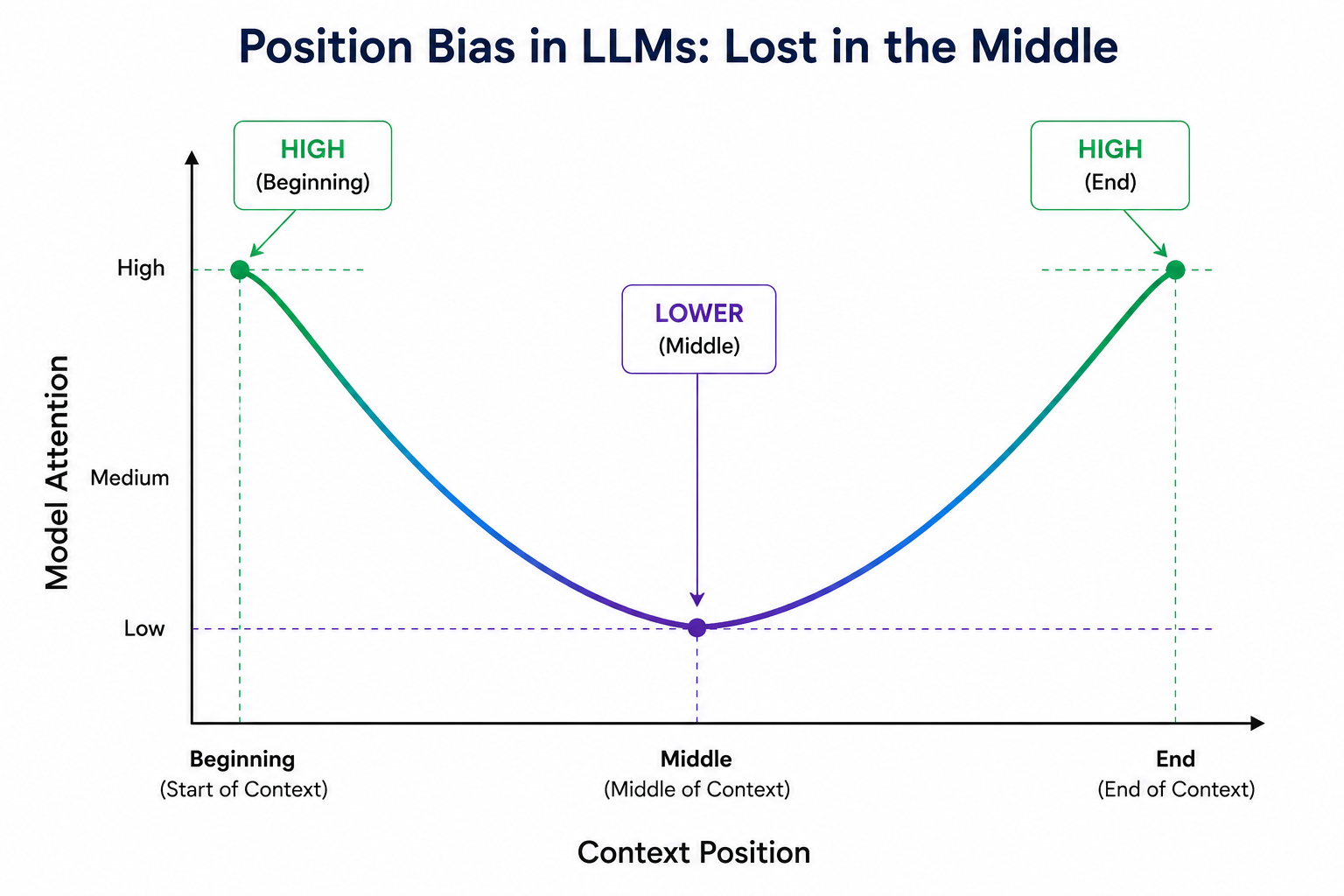
This is extremely important.
During training, the model develops a statistical bias where, most of the time, it learns:
- Beginning of the prompt, which contains: instructions, system prompts, task definitions
- End of the prompt, which contains: latest user query, final instructions, output format
This creates primacy bias and recency bias.
This is why relevant middle chunks get ignored in the context.
3. Softmax competition
As we know, attention uses softmax to compute probabilities to understand which word has more relevance with another word.
So if all chunks are somewhat similar, for example:
Chunk A → loan approved history Chunk B → customer income Chunk C → blacklist status Chunk D → repayment notes Chunk E → risk score
Here, if we see all chunks are somewhat important, then the model may fail to strongly prioritize “blacklist status”, especially if it is hidden in the middle.
4. Similarity interference
Another very important cause of this failure is passing too many similar chunks or duplicate information.
If similar chunks are passed, the model gets confused and then ignores information in the middle, even if that information is important or relevant to the query.
These are the most important reasons why the Lost in the Middle failure happens.
How to detect the “Lost in the Middle” issue
Knowing how to detect this problem is important because if we know how to detect it, then we can create test cases around it and do thorough testing before production.
So let’s understand how to detect this.
Needle-in-a-Haystack Test
This is the classic test, where:
- Create a large noisy context
- Hide one important/relevant fact
- Ask the LLM a question about it
- Move the fact across positions
- Measure the accuracy
Move the critical fact to:
| Test | Position |
|---|---|
| Test 1 | Beginning |
| Test 2 | Middle |
| Test 3 | End |
The expected healthy behavior would be that all tests should generate similar output.
A typical bad result will look like:
| Position | Accuracy |
|---|---|
| Beginning | 95% |
| Middle | 61% |
| End | 92% |
This clearly indicates:
Now let’s look at some production-ready test cases we can plan so that the system does not get pushed to production with this issue.
These are a few popular test strategies:
1. Position Sensitivity Testing
This directly measures Lost in the Middle.
Here, we work with two parts:
- Relevant chunks: These contain the important information required to answer the question.
- Distractor chunks: Dummy information that is false and not relevant to the question, which acts as noise.
Now the idea is to move the relevant chunk systematically:
Beginning: relevant noise noise noise Middle: noise noise relevant noise End: noise noise noise relevant
Using this, we can measure:
- Answer correctness
- Citation correctness
- Hallucination rate
- Confidence
2. Retrieval Attribution Testing
This testing type is very important for RAG.
Here, first we test if the retriever is giving us the correct chunk, then we test whether the LLM is using that correct chunk to answer the question.
For every response, we track:
| Metric | Meaning |
|---|---|
| Retrieved chunk | What the retriever fetched |
| Used chunk | What the model actually referenced |
| Gold chunk | True supporting evidence |
The goal of this testing is:
This is very critical.
Using this testing approach, we can avoid failures like Lost in the Middle.
3. Long Context Scaling Tests
This tests:
Example:
Run the same QA task with:
| Tokens | Accuracy |
|---|---|
| 5k | 96% |
| 20k | 92% |
| 50k | 84% |
| 100k | 67% |
This shows:
- Context saturation point
- Production limits
Many teams ignore this.
They see:
and assume:
These are very different things.
Now that we know what Lost in the Middle is, how to detect it, and how to build test cases around it, we will now understand how to solve or avoid this issue from appearing.
How to solve it
1. Re-ranking (This is very important)
A very simple trick: before sending chunks to the LLM, rank them using a re-ranker model and keep the relevant chunks on top.
Instead of:
1 irrelevant 2 irrelevant 3 important 4 irrelevant
Make:
1 IMPORTANT 2 supporting 3 supporting 4 less relevant
This alone improves performance massively.
Here, latency and cost may increase due to the additional re-ranking layer.
2. Context Compression
Do not dump the entire raw PDF into the context and ask questions.
Use proper relevant topics, summarized topics, extract facts using similarity search or a vector database, and pass only relevant information to the LLM.
Use:
- Summaries
- Extracted facts
- Structured evidence
- Metadata filtering
Bad:
Better:
3. Chunking Strategy
Poor chunking causes Lost in the Middle.
Good chunking:
- Semantic boundaries
- Overlap
- Smaller focused chunks
- Preserve meaning
Bad:
Better:
4. Instruction Anchoring
Repeat critical instructions near the end.
Example:
IMPORTANT: You MUST verify blacklist status before approval.
Place it near the final query.
5. Retrieval-Augmented Prompt Templates
Instead of raw chunks:
Evidence 1: ... Evidence 2: ... MOST RELEVANT EVIDENCE: ...
Guide model attention explicitly.
6. Use Structured Outputs
Instead of asking:
What's wrong?
Ask:
{
"rule_checked": "...",
"evidence_used": "...",
"mismatch_found": true
}
This forces grounding.
7. Multi-Step Reasoning
Agentic systems can:
- Retrieve
- Extract evidence
- Validate evidence
- Reason
- Critique result
Instead of using one giant prompt.
This is where Agentic AI becomes valuable.
These are some important concepts to solve this issue.
Conclusion
The Lost-in-the-Middle problem directly impacts the accuracy of the response.
To solve this problem, first we need to know how to detect it.
Then, we need to work creatively on context design and solve this problem by making the context smaller and more relevant.
There are many ways to solve this, some of which are listed above, but creative and skilled engineers solve it in their own way, which best fits the system being built.
If you want to discuss AI Engineering, RAG systems, Agentic AI, or LLM production systems, feel free to connect with me:
LinkedIn: https://www.linkedin.com/in/veer-khot-93177bab/
Website: veerkhot.com
← Back to Articles